
datarepo: a simple platform for complex data¶
datarepo is a simple query interface for multimodal data at any scale.
With datarepo, you can define a catalog, databases, and tables to query any existing data source. Once you've defined your catalog, you can spin up a static site for easy browsing or a read-only API for programmatic access. No running servers or services!
The datarepo catalog has native, declarative connectors to Delta Lake and Parquet stores. datarepo also supports defining tables via custom Python functions, so you can connect to any data source!
Here's an example catalog:
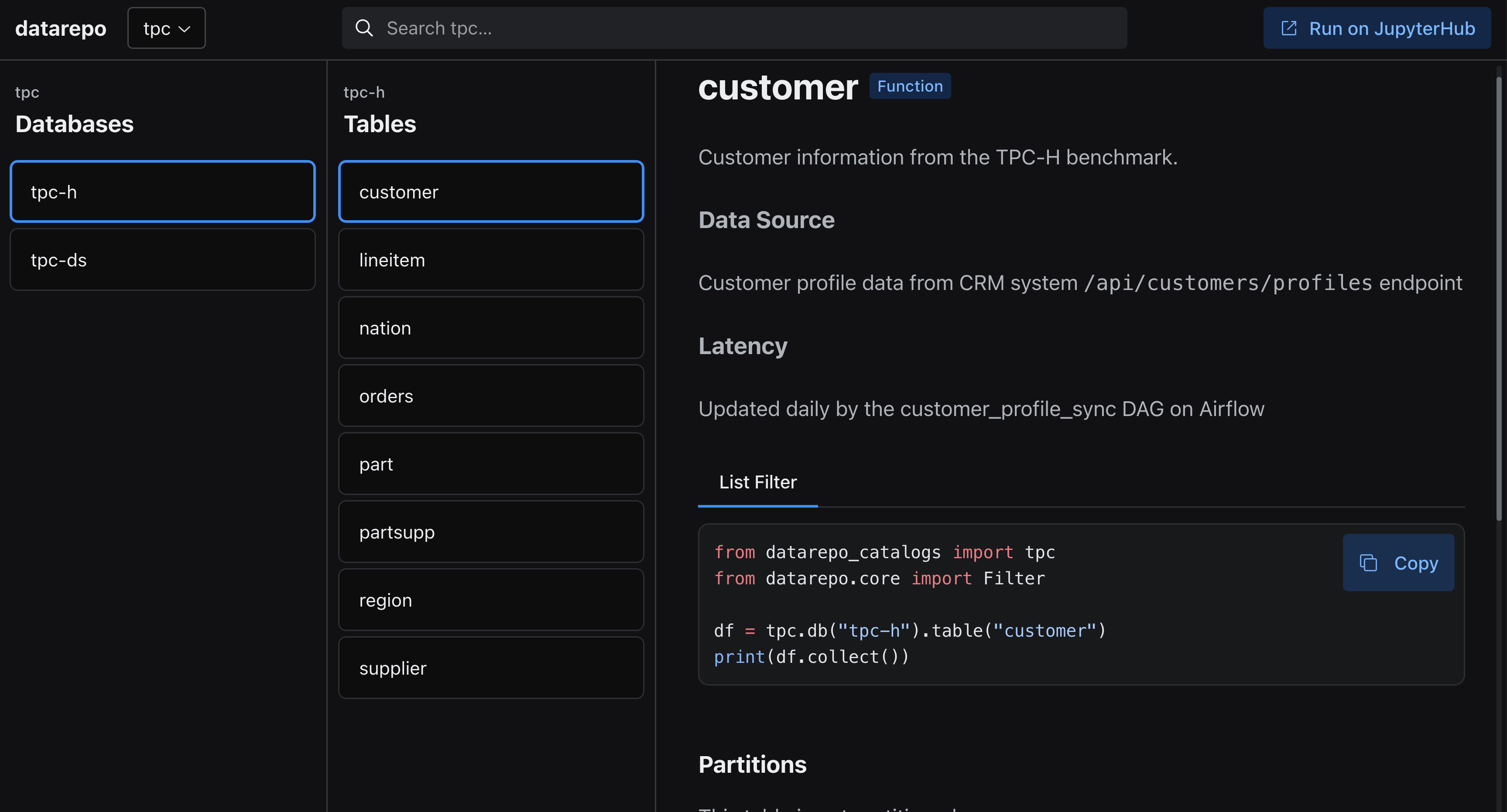
Key features¶
- Unified interface: Query data across different storage modalities (Parquet, DeltaLake, relational databases)
- Declarative catalog syntax: Define catalogs in python without running services
- Catalog site generation: Generate a static site catalog for visual browsing
- Extensible: Declare tables as custom python functions for querying any data
- API support: Generate a YAML config for querying with ROAPI
- Fast: Uses Rust-native libraries such as polars, delta-rs, and Apache DataFusion for performant reads
Philosophy¶
Data engineering should be simple. That means:
- Scale up and scale down - tools should scale down to a developer's laptop and up to stateless clusters
- Prioritize local development experience - use composable libraries instead of distributed services
- Code as a catalog - define tables in code, generate a static site catalog and APIs without running services
Quick start¶
Install the latest version with:
pip install data-repository
Create a table and catalog¶
First, create a module to define your tables (e.g., tpch_tables.py):
# tpch_tables.py
from datarepo.core import (
DeltalakeTable,
ParquetTable,
Filter,
table,
NlkDataFrame,
Partition,
PartitioningScheme,
)
import pyarrow as pa
import polars as pl
# Delta Lake backed table
part = DeltalakeTable(
name="part",
uri="s3://my-bucket/tpc-h/part",
schema=pa.schema(
[
("p_partkey", pa.int64()),
("p_name", pa.string()),
("p_mfgr", pa.string()),
("p_brand", pa.string()),
("p_type", pa.string()),
("p_size", pa.int32()),
("p_container", pa.string()),
("p_retailprice", pa.decimal128(12, 2)),
("p_comment", pa.string()),
]
),
docs_filters=[
Filter("p_partkey", "=", 1),
Filter("p_brand", "=", "Brand#1"),
],
unique_columns=["p_partkey"],
description="""
Part information from the TPC-H benchmark.
Contains details about parts including name, manufacturer, brand, and retail price.
""",
table_metadata_args={
"data_input": "Part catalog data from manufacturing systems, updated daily",
"latency_info": "Daily batch updates from manufacturing ERP system",
"example_notebook": "https://example.com/notebooks/part_analysis.ipynb",
},
)
# Table defined as a function
@table(
data_input="Supplier master data from vendor management system <code>/api/suppliers/master</code> endpoint",
latency_info="Updated weekly by the supplier_master_sync DAG on Airflow",
)
def supplier() -> NlkDataFrame:
"""Supplier information from the TPC-H benchmark."""
data = {
"s_suppkey": [1, 2, 3, 4, 5],
"s_name": [
"Supplier#1",
"Supplier#2",
],
"s_address": [
"123 Main St",
"456 Oak Ave",
],
"s_nationkey": [1, 1],
"s_phone": ["555-0001", "555-0002"],
"s_acctbal": [1000.00, 2000.00],
"s_comment": ["Comment 1", "Comment 2"],
}
return pl.LazyFrame(data)
# tpch_catalog.py
from datarepo.core import Catalog, ModuleDatabase
import tpch_tables
# Create a catalog
dbs = {"tpc-h": ModuleDatabase(tpch_tables)}
TPCHCatalog = Catalog(dbs)
Query the data¶
>>> from tpch_catalog import TPCHCatalog
>>> from datarepo.core import Filter
>>>
>>> # Get part and supplier information
>>> part_data = TPCHCatalog.db("tpc-h").table(
... "part",
... (
... Filter('p_partkey', 'in', [1, 2, 3, 4]),
... Filter('p_brand', 'in', ['Brand#1', 'Brand#2', 'Brand#3']),
... ),
... )
>>>
>>> supplier_data = TPCHCatalog.db("tpc-h").table("supplier")
>>>
>>> # Join part and supplier data and select specific columns
>>> joined_data = part_data.join(
... supplier_data,
... left_on="p_partkey",
... right_on="s_suppkey",
... ).select(["p_name", "p_brand", "s_name"]).collect()
>>>
>>> print(joined_data)
shape: (4, 3)
┌────────────┬────────────┬────────────┐
│ p_name │ p_brand │ s_name │
│ --- │ --- │ --- │
│ str │ str │ str │
╞════════════╪════════════╪════════════╡
│ Part#1 │ Brand#1 │ Supplier#1 │
│ Part#2 │ Brand#2 │ Supplier#2 │
│ Part#3 │ Brand#3 │ Supplier#3 │
│ Part#4 │ Brand#1 │ Supplier#4 │
└────────────┴────────────┴────────────┘
Generate a static site catalog¶
You can export your catalog to a static site with a single command:
# export.py
from datarepo.export.web import export_and_generate_site
from tpch_catalog import TPCHCatalog
# Export and generate the site
export_and_generate_site(
catalogs=[("tpch", TPCHCatalog)], output_dir=str(output_dir)
)
Generate an API¶
You can also generate a YAML configuration for ROAPI:
from datarepo.export import roapi
from tpch_catalog import TPCHCatalog
# Generate ROAPI config
roapi.generate_config(TPCHCatalog, output_file="roapi-config.yaml")
About Neuralink¶
datarepo is part of Neuralink's commitment to the open source community. By maintaining free and open source software, we aim to accelerate data engineering and biotechnology.
Neuralink is creating a generalized brain interface to restore autonomy to those with unmet medical needs today, and to unlock human potential tomorrow.
You don't have to be a brain surgeon to work at Neuralink. We are looking for exceptional individuals from many fields, including software and data engineering. Learn more at neuralink.com/careers.